

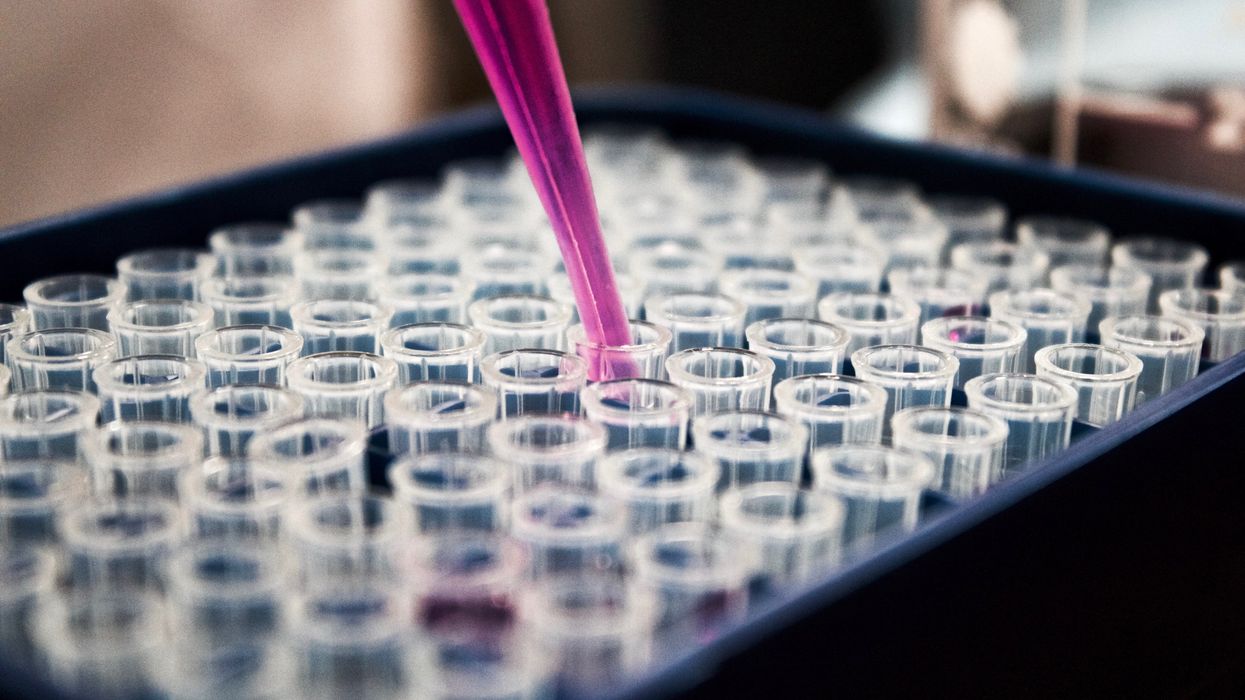
The test tubes contain tiny DNA/enzyme-based circuits, which comprise TRUMPET, a new type of electronic device, smaller than a cell.
While a computer gives these inputs in binary code or "bits," such as a 0 or 1, biocomputing uses DNA strands as inputs, whether double or single-stranded, and often uses fluorescent RNA as an output.
Adamala’s research focuses on developing such biocomputing systems using DNA, RNA, proteins, and lipids. Using these molecules in the biocomputing systems allows the latter to be biocompatible with the human body, resulting in a natural healing process. In a recent Nature Communications study, Adamala and her team created a new biocomputing platform called TRUMPET (Transcriptional RNA Universal Multi-Purpose GatE PlaTform) which acts like a DNA-powered computer chip. “These biological systems can heal if you design them correctly,” adds Adamala. “So you can imagine a computer that will eventually heal itself.”
The basics of biocomputing
Biocomputing and regular computing have many similarities. Like regular computing, biocomputing works by running information through a series of gates, usually logic gates. A logic gate works as a fork in the road for an electronic circuit. The input will travel one way or another, giving two different outputs. An example logic gate is the AND gate, which has two inputs (A and B) and two different results. If both A and B are 1, the AND gate output will be 1. If only A is 1 and B is 0, the output will be 0 and vice versa. If both A and B are 0, the result will be 0. While a computer gives these inputs in binary code or "bits," such as a 0 or 1, biocomputing uses DNA strands as inputs, whether double or single-stranded, and often uses fluorescent RNA as an output. In this case, the DNA enters the logic gate as a single or double strand.
If the DNA is double-stranded, the system “digests” the DNA or destroys it, which results in non-fluorescence or “0” output. Conversely, if the DNA is single-stranded, it won’t be digested and instead will be copied by several enzymes in the biocomputing system, resulting in fluorescent RNA or a “1” output. And the output for this type of binary system can be expanded beyond fluorescence or not. For example, a “1” output might be the production of the enzyme insulin, while a “0” may be that no insulin is produced. “This kind of synergy between biology and computation is the essence of biocomputing,” says Stephanie Forrest, a professor and the director of the Biodesign Center for Biocomputing, Security and Society at Arizona State University.
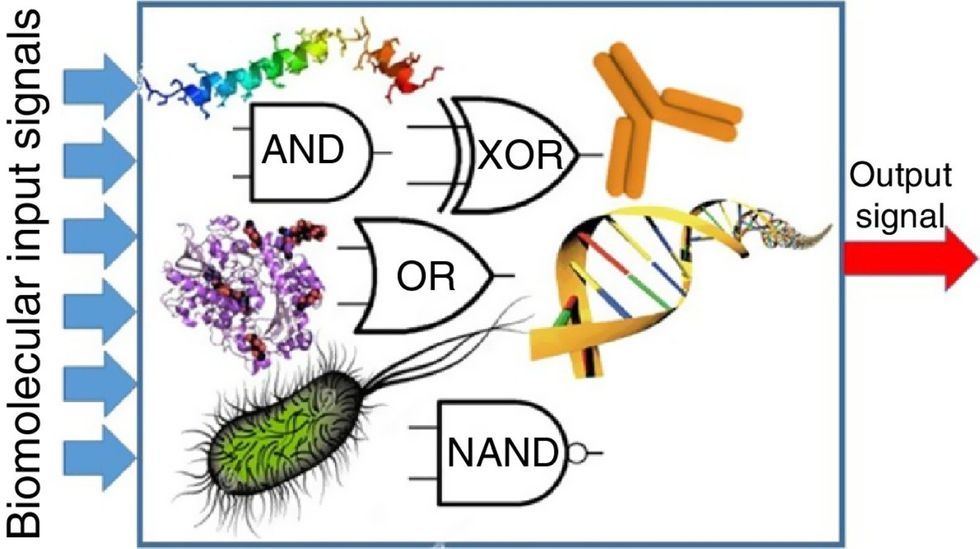
Biocomputing circles are made of DNA, RNA, proteins and even bacteria.
Evgeny Katz
The TRUMPET’s promise
Depending on whether the biocomputing system is placed directly inside a cell within the human body, or run in a test-tube, different environmental factors play a role. When an output is produced inside a cell, the cell's natural processes can amplify this output (for example, a specific protein or DNA strand), creating a solid signal. However, these cells can also be very leaky. “You want the cells to do the thing you ask them to do before they finish whatever their businesses, which is to grow, replicate, metabolize,” Adamala explains. “However, often the gate may be triggered without the right inputs, creating a false positive signal. So that's why natural logic gates are often leaky." While biocomputing outside a cell in a test tube can allow for tighter control over the logic gates, the outputs or signals cannot be amplified by a cell and are less potent.
TRUMPET, which is smaller than a cell, taps into both cellular and non-cellular biocomputing benefits. “At its core, it is a nonliving logic gate system,” Adamala states, “It's a DNA-based logic gate system. But because we use enzymes, and the readout is enzymatic [where an enzyme replicates the fluorescent RNA], we end up with signal amplification." This readout means that the output from the TRUMPET system, a fluorescent RNA strand, can be replicated by nearby enzymes in the platform, making the light signal stronger. "So it combines the best of both worlds,” Adamala adds.
These organic-based systems could detect cancer cells or low insulin levels inside a patient’s body.
The TRUMPET biocomputing process is relatively straightforward. “If the DNA [input] shows up as single-stranded, it will not be digested [by the logic gate], and you get this nice fluorescent output as the RNA is made from the single-stranded DNA, and that's a 1,” Adamala explains. "And if the DNA input is double-stranded, it gets digested by the enzymes in the logic gate, and there is no RNA created from the DNA, so there is no fluorescence, and the output is 0." On the story's leading image above, if the tube is "lit" with a purple color, that is a binary 1 signal for computing. If it's "off" it is a 0.
While still in research, TRUMPET and other biocomputing systems promise significant benefits to personalized healthcare and medicine. These organic-based systems could detect cancer cells or low insulin levels inside a patient’s body. The study’s lead author and graduate student Judee Sharon is already beginning to research TRUMPET's ability for earlier cancer diagnoses. Because the inputs for TRUMPET are single or double-stranded DNA, any mutated or cancerous DNA could theoretically be detected from the platform through the biocomputing process. Theoretically, devices like TRUMPET could be used to detect cancer and other diseases earlier.
Adamala sees TRUMPET not only as a detection system but also as a potential cancer drug delivery system. “Ideally, you would like the drug only to turn on when it senses the presence of a cancer cell. And that's how we use the logic gates, which work in response to inputs like cancerous DNA. Then the output can be the production of a small molecule or the release of a small molecule that can then go and kill what needs killing, in this case, a cancer cell. So we would like to develop applications that use this technology to control the logic gate response of a drug’s delivery to a cell.”
Although platforms like TRUMPET are making progress, a lot more work must be done before they can be used commercially. “The process of translating mechanisms and architecture from biology to computing and vice versa is still an art rather than a science,” says Forrest. “It requires deep computer science and biology knowledge,” she adds. “Some people have compared interdisciplinary science to fusion restaurants—not all combinations are successful, but when they are, the results are remarkable.”

Crickets are low on fat, high on protein, and can be farmed sustainably. They are also crunchy.
Listen on Apple | Listen on Spotify | Listen on Stitcher | Listen on Amazon | Listen on Google
Further reading:
More info on Bicky Nguyen
https://yseali.fulbright.edu.vn/en/faculty/bicky-n...
The environmental footprint of beef production
https://www.earthsave.org/environment.htm
https://www.watercalculator.org/news/articles/beef-king-big-water-footprints/
https://www.frontiersin.org/articles/10.3389/fsufs.2019.00005/full
https://ourworldindata.org/carbon-footprint-food-methane
Insect farming as a source of sustainable protein
https://www.insectgourmet.com/insect-farming-growing-bugs-for-protein/
https://www.sciencedirect.com/topics/agricultural-and-biological-sciences/insect-farming
Cricket flour is taking the world by storm
https://www.cricketflours.com/
https://talk-commerce.com/blog/what-brands-use-cricket-flour-and-why/
