

A future app may help you avoid getting the flu by informing you of your local risk on a given day.
Applied mathematician Sara del Valle works at the U.S.'s foremost nuclear weapons lab: Los Alamos. Once colloquially called Atomic City, it's a hidden place 45 minutes into the mountains northwest of Santa Fe. Here, engineers developed the first atomic bomb.
Like AccuWeather, an app for disease prediction could help people alter their behavior to live better lives.
Today, Los Alamos still a small science town, though no longer a secret, nor in the business of building new bombs. Instead, it's tasked with, among other things, keeping the stockpile of nuclear weapons safe and stable: not exploding when they're not supposed to (yes, please) and exploding if someone presses that red button (please, no).
Del Valle, though, doesn't work on any of that. Los Alamos is also interested in other kinds of booms—like the explosion of a contagious disease that could take down a city. Predicting (and, ideally, preventing) such epidemics is del Valle's passion. She hopes to develop an app that's like AccuWeather for germs: It would tell you your chance of getting the flu, or dengue or Zika, in your city on a given day. And like AccuWeather, it could help people alter their behavior to live better lives, whether that means staying home on a snowy morning or washing their hands on a sickness-heavy commute.

Sara del Valle of Los Alamos is working to predict and prevent epidemics using data and machine learning.
Since the beginning of del Valle's career, she's been driven by one thing: using data and predictions to help people behave practically around pathogens. As a kid, she'd always been good at math, but when she found out she could use it to capture the tentacular spread of disease, and not just manipulate abstractions, she was hooked.
When she made her way to Los Alamos, she started looking at what people were doing during outbreaks. Using social media like Twitter, Google search data, and Wikipedia, the team started to sift for trends. Were people talking about hygiene, like hand-washing? Or about being sick? Were they Googling information about mosquitoes? Searching Wikipedia for symptoms? And how did those things correlate with the spread of disease?
It was a new, faster way to think about how pathogens propagate in the real world. Usually, there's a 10- to 14-day lag in the U.S. between when doctors tap numbers into spreadsheets and when that information becomes public. By then, the world has moved on, and so has the disease—to other villages, other victims.
"We found there was a correlation between actual flu incidents in a community and the number of searches online and the number of tweets online," says del Valle. That was when she first let herself dream about a real-time forecast, not a 10-days-later backcast. Del Valle's group—computer scientists, mathematicians, statisticians, economists, public health professionals, epidemiologists, satellite analysis experts—has continued to work on the problem ever since their first Twitter parsing, in 2011.
They've had their share of outbreaks to track. Looking back at the 2009 swine flu pandemic, they saw people buying face masks and paying attention to the cleanliness of their hands. "People were talking about whether or not they needed to cancel their vacation," she says, and also whether pork products—which have nothing to do with swine flu—were safe to buy.
At the latest meeting with all the prediction groups, del Valle's flu models took first and second place.
They watched internet conversations during the measles outbreak in California. "There's a lot of online discussion about anti-vax sentiment, and people trying to convince people to vaccinate children and vice versa," she says.
Today, they work on predicting the spread of Zika, Chikungunya, and dengue fever, as well as the plain old flu. And according to the CDC, that latter effort is going well.
Since 2015, the CDC has run the Epidemic Prediction Initiative, a competition in which teams like de Valle's submit weekly predictions of how raging the flu will be in particular locations, along with other ailments occasionally. Michael Johannson is co-founder and leader of the program, which began with the Dengue Forecasting Project. Its goal, he says, was to predict when dengue cases would blow up, when previously an area just had a low-level baseline of sick people. "You'll get this massive epidemic where all of a sudden, instead of 3,000 to 4,000 cases, you have 20,000 cases," he says. "They kind of come out of nowhere."
But the "kind of" is key: The outbreaks surely come out of somewhere and, if scientists applied research and data the right way, they could forecast the upswing and perhaps dodge a bomb before it hit big-time. Questions about how big, when, and where are also key to the flu.
A big part of these projects is the CDC giving the right researchers access to the right information, and the structure to both forecast useful public-health outcomes and to compare how well the models are doing. The extra information has been great for the Los Alamos effort. "We don't have to call departments and beg for data," says del Valle.
When data isn't available, "proxies"—things like symptom searches, tweets about empty offices, satellite images showing a green, wet, mosquito-friendly landscape—are helpful: You don't have to rely on anyone's health department.
At the latest meeting with all the prediction groups, del Valle's flu models took first and second place. But del Valle wants more than weekly numbers on a government website; she wants that weather-app-inspired fortune-teller, incorporating the many diseases you could get today, standing right where you are. "That's our dream," she says.

This plot shows the the correlations between the online data stream, from Wikipedia, and various infectious diseases in different countries. The results of del Valle's predictive models are shown in brown, while the actual number of cases or illness rates are shown in blue.
(Courtesy del Valle)
The goal isn't to turn you into a germophobic agoraphobe. It's to make you more aware when you do go out. "If you know it's going to rain today, you're more likely to bring an umbrella," del Valle says. "When you go on vacation, you always look at the weather and make sure you bring the appropriate clothing. If you do the same thing for diseases, you think, 'There's Zika spreading in Sao Paulo, so maybe I should bring even more mosquito repellent and bring more long sleeves and pants.'"
They're not there yet (don't hold your breath, but do stop touching your mouth). She estimates it's at least a decade away, but advances in machine learning could accelerate that hypothetical timeline. "We're doing baby steps," says del Valle, starting with the flu in the U.S., dengue in Brazil, and other efforts in Colombia, Ecuador, and Canada. "Going from there to forecasting all diseases around the globe is a long way," she says.
But even AccuWeather started small: One man began predicting weather for a utility company, then helping ski resorts optimize their snowmaking. His influence snowballed, and now private forecasting apps, including AccuWeather's, populate phones across the planet. The company's progression hasn't been without controversy—privacy incursions, inaccuracy of long-term forecasts, fights with the government—but it has continued, for better and for worse.
Disease apps, perhaps spun out of a small, unlikely team at a nuclear-weapons lab, could grow and breed in a similar way. And both the controversies and public-health benefits that may someday spin out of them lie in the future, impossible to predict with certainty.

Alida de Flamingh and her team are collecting elephant dung. It holds a trove of information about animal health, diet and genetic diversity.
Approximately 27 percent of mammals and 28 percent of all assessed species are close to dying out. The IUCN Red List of threatened species, simply called the Red List, is the world’s most comprehensive record of animals’ risk of extinction status. The more information scientists gather, the better their chances of reducing those risks. In Africa, populations of vertebrates declined 69 percent between 1970 and 2022, according to the World Wildlife Fund (WWF).
“We put on sterile gloves and use a sterile swab to collect wet mucus and materials from the outside of the dung ball,” says Alida de Flamingh, a postdoctoral researcher at the University of Illinois Urbana-Champaign.
“When people talk about species, they often talk about ecosystems, but they often overlook genetic diversity,” says Christina Hvilsom, senior geneticist at the Copenhagen Zoo. “It’s easy to count (individuals) to assess whether the population size is increasing or decreasing, but diversity isn’t something we can see with our bare eyes. Yet, it’s actually the foundation for the species and populations.” DNA analysis can provide this critical information.
Assessing elephants’ health
“Africa’s elephant populations are facing unprecedented threats,” says de Flamingh, the postdoc, who has studied them since 2009. Challenges include ivory poaching, habitat destruction and smaller, more fragmented habitats that result in smaller mating pools with less genetic diversity. Additionally, de Flamingh studies the microbial communities living on and in elephants – their microbiomes – looking for parasites or dangerous microbes.
Approximately 415,000 elephants inhabit Africa today, but de Flamingh says the number would be four times higher without these challenges. The IUCN Red List reports African savannah elephants are endangered and African forest elephants are critically endangered. Elephants support ecosystem biodiversity by clearing paths that help other species travel. Their very footprints create small puddles that can host smaller organisms such as tadpoles. Elephants are often described as ecosystems’ engineers, so if they disappear, the rest of the ecosystem will suffer too.
There’s a process to collecting elephant feces. “We put on sterile gloves (which we change for each sample) and use a sterile swab to collect wet mucus and materials from the outside of the dung ball,” says de Flamingh. They rub a sample about the size of a U.S. quarter onto a paper card embedded with DNA preservation technology. Each card is air dried and stored in a packet of desiccant to prevent mold growth. This way, samples can be stored at room temperature indefinitely without the DNA degrading.
Earlier methods required collecting dung in bags, which needed either refrigeration or the addition of preservatives, or the riskier alternative of tranquilizing the animals before approaching them to draw blood samples. The ability to collect and sequence the DNA made things much easier and safer.
“Our research provides a way to assess elephant health without having to physically interact with elephants,” de Flamingh emphasizes. “We also keep track of the GPS coordinates of each sample so that we can create a map of the sampling locations,” she adds. That helps researchers correlate elephants’ health with geographic areas and their conditions.
Although de Flamingh works with elephants in the wild, the contributions of zoos in the United States and collaborations in South Africa (notably the late Professor Rudi van Aarde and the Conservation Ecology Research Unit at the University of Pretoria) were key in studying this method to ensure it worked, she points out.
Protecting chimpanzees
Genetic work with chimpanzees began about a decade ago. Hvilsom and her group at the Copenhagen Zoo analyzed DNA from nearly 1,000 fecal samples collected between 2003 and 2018 by a team of international researchers. The goal was to assess the status of the West African subspecies, which is critically endangered after rapid population declines. Of the four subspecies of chimpanzees, the West African subspecies is considered the most at-risk.
In total, the WWF estimates the numbers of chimpanzees inhabiting Africa’s forests and savannah woodlands at between 173,000 and 300,000. Poaching, disease and human-caused changes to their lands are their major risks.
By analyzing genetics obtained from fecal samples, Hvilsom estimated the chimpanzees’ population, ascertained their family relationships and mapped their migration routes.
“One of the threats is mining near the Nimba Mountains in Guinea,” a stronghold for the West African subspecies, Hvilsom says. The Nimba Mountains are a UNESCO World Heritage Site, but they are rich in iron ore, which is used to make the steel that is vital to the Asian construction boom. As she and colleagues wrote in a recent paper, “Many extractive industries are currently developing projects in chimpanzee habitat.”
Analyzing DNA allows researchers to identify individual chimpanzees more accurately than simply observing them, she says. Normally, field researchers would install cameras and manually inspect each picture to determine how many chimpanzees were in an area. But, Hvilsom says, “That’s very tricky. Chimpanzees move a lot and are fast, so it’s difficult to get clear pictures. Often, they find and destroy the cameras. Also, they live in large areas, so you need a lot of cameras.”
By analyzing genetics obtained from fecal samples, Hvilsom estimated the chimpanzees’ population, ascertained their family relationships and mapped their migration routes based upon DNA comparisons with other chimpanzee groups. The mining companies and builders are using this information to locate future roads where they won’t disrupt migration – a more effective solution than trying to build artificial corridors for wildlife.
“The current route cuts off communities of chimpanzees,” Hvilsom elaborates. That effectively prevents young adult chimps from joining other groups when the time comes, eventually reducing the currently-high levels of genetic diversity.
“The mining company helped pay for the genetics work,” Hvilsom says, “as part of its obligation to assess and monitor biodiversity and the effect of the mining in the area.”
Of 50 toucan subspecies, 11 are threatened or near-threatened with extinction because of deforestation and poaching.
Identifying toucan families
Feces aren't the only substance researchers draw DNA samples from. Jeffrey Coleman, a Ph.D. candidate at the University of Texas at Austin relies on blood tests for studying the genetic diversity of toucans---birds species native to Central America and nearby regions. They live in the jungles, where they hop among branches, snip fruit from trees, toss it in the air and catch it with their large beaks. “Toucans are beautiful, charismatic birds that are really important to the ecosystem,” says Coleman.
Of their 50 subspecies, 11 are threatened or near-threatened with extinction because of deforestation and poaching. “When people see these aesthetically pleasing birds, they’re motivated to care about conservation practices,” he points out.
Coleman works with the Dallas World Aquarium and its partner zoos to analyze DNA from blood draws, using it to identify which toucans are related and how closely. His goal is to use science to improve the genetic diversity among toucan offspring.
Specifically, he’s looking at sections of the genome of captive birds in which the nucleotides repeat multiple times, such as AGATAGATAGAT. Called microsatellites, these consecutively-repeating sections can be passed from parents to children, helping scientists identify parent-child and sibling-sibling relationships. “That allows you to make strategic decisions about how to pair (captive) individuals for mating...to avoid inbreeding,” Coleman says.

Jeffrey Coleman is studying the microsatellites inside the toucan genomes.
Courtesy Jeffrey Coleman
The alternative is to use a type of analysis that looks for a single DNA building block – a nucleotide – that differs in a given sequence. Called single nucleotide polymorphisms (SNPs, pronounced “snips”), they are very common and very accurate. Coleman says they are better than microsatellites for some uses. But scientists have already developed a large body of microsatellite data from multiple species, so microsatellites can shed more insights on relations.
Regardless of whether conservation programs use SNPs or microsatellites to guide captive breeding efforts, the goal is to help them build genetically diverse populations that eventually may supplement endangered populations in the wild. “The hope is that the ecosystem will be stable enough and that the populations (once reintroduced into the wild) will be able to survive and thrive,” says Coleman. History knows some good examples of captive breeding success.
The California condor, which had a total population of 27 in 1987, when the last wild birds were captured, is one of them. A captive breeding program boosted their numbers to 561 by the end of 2022. Of those, 347 of those are in the wild, according to the National Park Service.
Conservationists hope that their work on animals’ genetic diversity will help preserve and restore endangered species in captivity and the wild. DNA analysis is crucial to both types of efforts. The ability to apply genome sequencing to wildlife conservation brings a new level of accuracy that helps protect species and gives fresh insights that observation alone can’t provide.
“A lot of species are threatened,” Coleman says. “I hope this research will be a resource people can use to get more information on longer-term genealogies and different populations.”
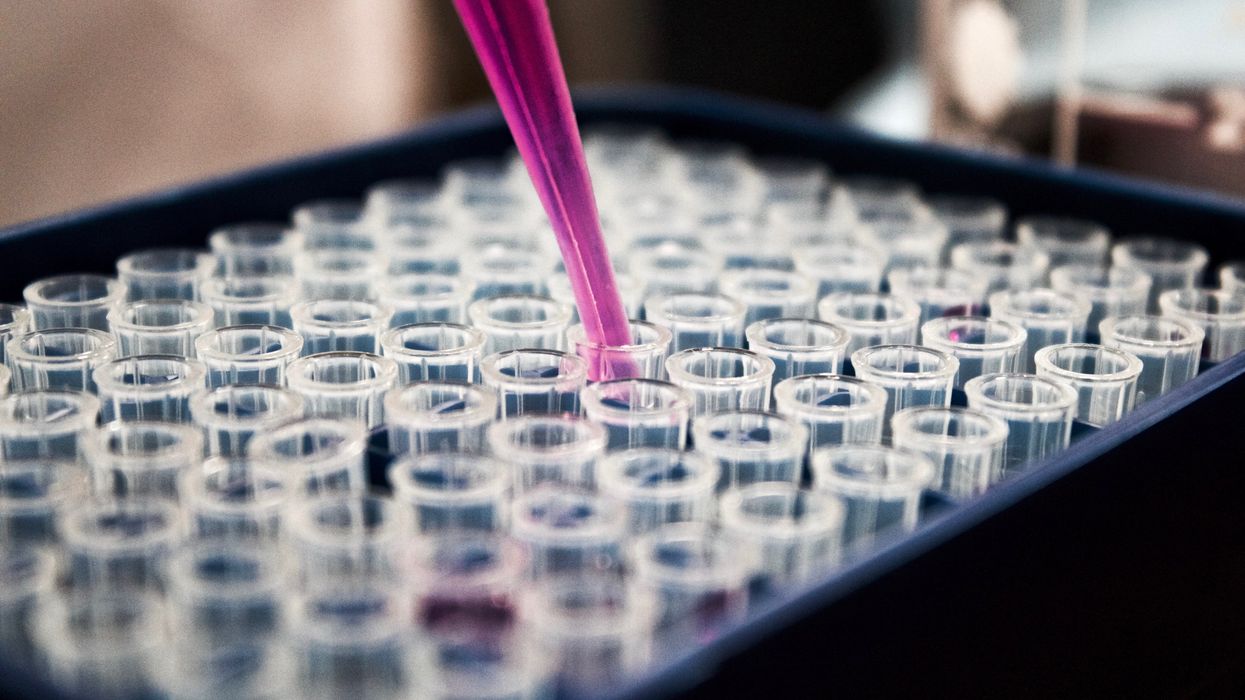
The test tubes contain tiny DNA/enzyme-based circuits, which comprise TRUMPET, a new type of electronic device, smaller than a cell.
While a computer gives these inputs in binary code or "bits," such as a 0 or 1, biocomputing uses DNA strands as inputs, whether double or single-stranded, and often uses fluorescent RNA as an output.
Adamala’s research focuses on developing such biocomputing systems using DNA, RNA, proteins, and lipids. Using these molecules in the biocomputing systems allows the latter to be biocompatible with the human body, resulting in a natural healing process. In a recent Nature Communications study, Adamala and her team created a new biocomputing platform called TRUMPET (Transcriptional RNA Universal Multi-Purpose GatE PlaTform) which acts like a DNA-powered computer chip. “These biological systems can heal if you design them correctly,” adds Adamala. “So you can imagine a computer that will eventually heal itself.”
The basics of biocomputing
Biocomputing and regular computing have many similarities. Like regular computing, biocomputing works by running information through a series of gates, usually logic gates. A logic gate works as a fork in the road for an electronic circuit. The input will travel one way or another, giving two different outputs. An example logic gate is the AND gate, which has two inputs (A and B) and two different results. If both A and B are 1, the AND gate output will be 1. If only A is 1 and B is 0, the output will be 0 and vice versa. If both A and B are 0, the result will be 0. While a computer gives these inputs in binary code or "bits," such as a 0 or 1, biocomputing uses DNA strands as inputs, whether double or single-stranded, and often uses fluorescent RNA as an output. In this case, the DNA enters the logic gate as a single or double strand.
If the DNA is double-stranded, the system “digests” the DNA or destroys it, which results in non-fluorescence or “0” output. Conversely, if the DNA is single-stranded, it won’t be digested and instead will be copied by several enzymes in the biocomputing system, resulting in fluorescent RNA or a “1” output. And the output for this type of binary system can be expanded beyond fluorescence or not. For example, a “1” output might be the production of the enzyme insulin, while a “0” may be that no insulin is produced. “This kind of synergy between biology and computation is the essence of biocomputing,” says Stephanie Forrest, a professor and the director of the Biodesign Center for Biocomputing, Security and Society at Arizona State University.
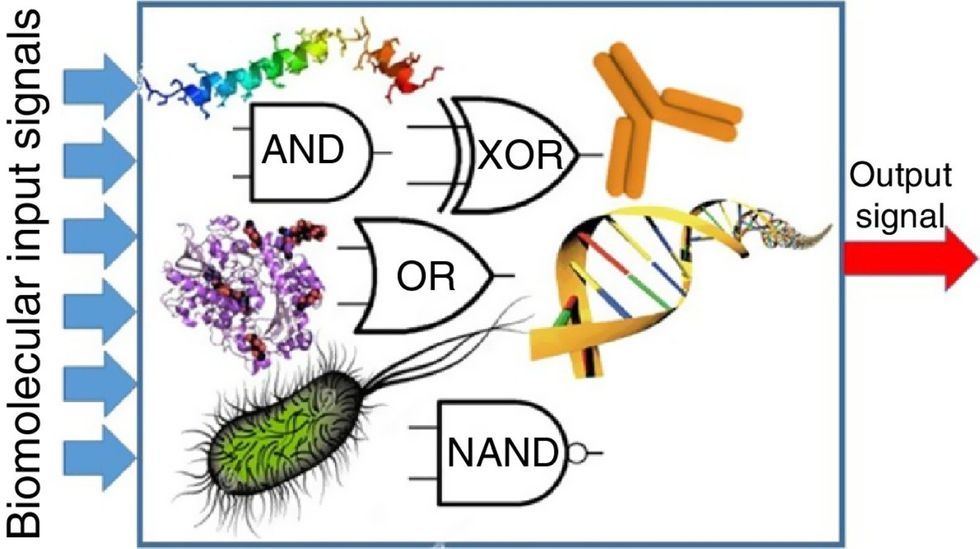
Biocomputing circles are made of DNA, RNA, proteins and even bacteria.
Evgeny Katz
The TRUMPET’s promise
Depending on whether the biocomputing system is placed directly inside a cell within the human body, or run in a test-tube, different environmental factors play a role. When an output is produced inside a cell, the cell's natural processes can amplify this output (for example, a specific protein or DNA strand), creating a solid signal. However, these cells can also be very leaky. “You want the cells to do the thing you ask them to do before they finish whatever their businesses, which is to grow, replicate, metabolize,” Adamala explains. “However, often the gate may be triggered without the right inputs, creating a false positive signal. So that's why natural logic gates are often leaky." While biocomputing outside a cell in a test tube can allow for tighter control over the logic gates, the outputs or signals cannot be amplified by a cell and are less potent.
TRUMPET, which is smaller than a cell, taps into both cellular and non-cellular biocomputing benefits. “At its core, it is a nonliving logic gate system,” Adamala states, “It's a DNA-based logic gate system. But because we use enzymes, and the readout is enzymatic [where an enzyme replicates the fluorescent RNA], we end up with signal amplification." This readout means that the output from the TRUMPET system, a fluorescent RNA strand, can be replicated by nearby enzymes in the platform, making the light signal stronger. "So it combines the best of both worlds,” Adamala adds.
These organic-based systems could detect cancer cells or low insulin levels inside a patient’s body.
The TRUMPET biocomputing process is relatively straightforward. “If the DNA [input] shows up as single-stranded, it will not be digested [by the logic gate], and you get this nice fluorescent output as the RNA is made from the single-stranded DNA, and that's a 1,” Adamala explains. "And if the DNA input is double-stranded, it gets digested by the enzymes in the logic gate, and there is no RNA created from the DNA, so there is no fluorescence, and the output is 0." On the story's leading image above, if the tube is "lit" with a purple color, that is a binary 1 signal for computing. If it's "off" it is a 0.
While still in research, TRUMPET and other biocomputing systems promise significant benefits to personalized healthcare and medicine. These organic-based systems could detect cancer cells or low insulin levels inside a patient’s body. The study’s lead author and graduate student Judee Sharon is already beginning to research TRUMPET's ability for earlier cancer diagnoses. Because the inputs for TRUMPET are single or double-stranded DNA, any mutated or cancerous DNA could theoretically be detected from the platform through the biocomputing process. Theoretically, devices like TRUMPET could be used to detect cancer and other diseases earlier.
Adamala sees TRUMPET not only as a detection system but also as a potential cancer drug delivery system. “Ideally, you would like the drug only to turn on when it senses the presence of a cancer cell. And that's how we use the logic gates, which work in response to inputs like cancerous DNA. Then the output can be the production of a small molecule or the release of a small molecule that can then go and kill what needs killing, in this case, a cancer cell. So we would like to develop applications that use this technology to control the logic gate response of a drug’s delivery to a cell.”
Although platforms like TRUMPET are making progress, a lot more work must be done before they can be used commercially. “The process of translating mechanisms and architecture from biology to computing and vice versa is still an art rather than a science,” says Forrest. “It requires deep computer science and biology knowledge,” she adds. “Some people have compared interdisciplinary science to fusion restaurants—not all combinations are successful, but when they are, the results are remarkable.”